

Press Release: SomniQ
May 19, 2026, 13:00 JST
See What You Couldn’t See in Your Own Practice.
Empatheme English Ear° Trail makes English practice visible, helping users from elementary school children to working adults see the hidden habits and causes behind their progress.

SomniQ Expands Empatheme English Ear° Trail
SomniQ Inc. (Chiyoda-ku, Tokyo; CEO: Rikko Sakaguchi) has expanded Empatheme English Ear° Trail, offered as an iOS and Android app, built on its patented technology for visualizing voice, cognition, and practice behavior.
With this release, SomniQ introduces new features that help users grow their “visible voice,” together with Empathy Interface Personal — a new interface that visualizes the entire practice process, including not only results but also the causes behind progress.
This release also presents the broader development of a new content medium born from the visualization of voice, with future expansions into English Ear° Kids, English Ear° Music, Japanese Ear° Trail, and Empallet.
Four new Visible-Practice experiences have been added in this release:
❶ Spoken lines grow like seeds. Flowers and fruits appear based on how closely users replicate the model’s voice.
❷ emp, a practice energy coin, accumulates through use. It can be spent on Rhythm Mirror feedback and personalized advice.
❸ The Watering Pot delivers individual guidance. Tutors provide comments and suggestions tailored to each user.
❹ Empathy Interface Personal visualizes the entire practice process. It reveals not only results, but also the causes behind progress.
Through these four experiences, users can begin to see practice habits and hidden factors that were previously invisible. When they can see, they can improve. As they improve, practice becomes enjoyable. That enjoyment supports continuity and drives further progress.
This is not mere visualization, nor is it gamification for its own sake. Empatheme English Ear° Trail is a new form of English practice — grounded in globally patented technology and practice data science — designed specifically to support sustained, effective practice.
Empatheme English Ear° Trail
Empatheme is a system invented to invite, guide, and encourage people into daily practice. It brings together globally patented technology that visualizes voice, cognition, actions, and practice behavior like a mirror, data science that reveals change and improvement, and an artful experience that lets users see, feel, and grow their own practice.
This is not a learning app that asks people to work hard without showing them their progress or its causes. Nor is it an app that simply adds surface-level game elements. Instead of relying on text and knowledge, Empatheme uses native English sound and rhythm as the guide. Users move forward by seeing, touching, and growing their own spoken lines as visible voice seeds.
Through this process, they become aware of the Japanese-based habits of hearing and processing English rhythm and sound, gradually reduce hidden habits, and experience the joy of acquiring usable English through practice.
Empatheme’s visualization is not a generic way of displaying practice data. What becomes visible is your own voice, your own habits, the flow of your change, and the causes behind what works and what does not.
With Empatheme, users can:
❶ See the sounds they are hearing — and the sounds they are missing.
❷ See their own voice, actions, practice behavior, and the flow of their change.
❸ See the whole practice process, from results to process to causes.
❹ See how closely they reproduce the model voice, and how their visible voice seeds grow through practice.
❺ See the path from personal reflection to direct interaction with tutors.
These forms of visualization are made possible by SomniQ’s globally patented technology, including Hearing Mirror, Rhythm Mirror, Context Mirror, Empathy Interface, and Empathetic AI KurageSan.
Please note that Empatheme®, Hearing Mirror®, Rhythm Mirror®, Context Mirror®, Empathy Interface®, and KurageSan® are registered trademarks of SomniQ Inc.
New Features for Growing Your Own Practice
⚫︎The Watering Pot: Request personal advice exactly where you need it

⚪︎“How can I say this part better?”
⚪︎“Why can’t I hear this sound?”
⚪︎“I thought I was saying it correctly — so what is different?”
The Watering Pot is a new feature that lets users mark a specific line and ask a tutor a focused question.
It is designed to help users “water” the exact place they have noticed, so their visible voice seeds can grow. Based on each user’s own practice data, tutors can provide feedback and encouragement that is not generic, but personal, specific, and grounded in actual practice.
⚫︎emp: Energy Coins That Grow Through Practice

s users continue the practice cycle — imitate, perform, and reflect — they earn emp, short for Empathetic Moment by Practice.
emp is not a random bonus point. It is an energy coin that visualizes each user’s practice and connects it to the next practice experience. Earned emp can be used to generate Rhythm Mirrors, request personal advice from tutors, and access other practice support.
In this way, the energy created through daily practice is returned to the user as services that directly support further improvement.
⚫︎Use emp to Expand the Practice Experience
emp can be earned through practice or purchased when needed. Users can use emp to move into richer practice experiences, including:
⚪︎Generating their own Rhythm Mirror in real time.
⚪︎Exchanging emp for personal advice through the Watering Pot.
⚪︎Accessing new Trail content in future updates.
⚫︎Spoken Lines Become Seeds That Grow

Seed → sprout → two leaves → flower → fruit
In English Ear° Trail, the lines users imitate grow as seeds. This is not a decorative effect. Based on RATIP, Empatheme’s original model for measuring speech replication, the degree of imitation is reflected in how each “visible voice” seed grows.
Instead of reacting to each individual score, users can see the condition and growth of their practice through the overall development, variation, and pattern of their seeds.
The Trail is built with:
⚪︎Natural model lines spoken by American high school and college students.
⚪︎Short phrases that are easy to hear, imitate, and speak aloud within about two seconds.
⚪︎Words and expressions that cover more than 90% of everyday English.
⚪︎Words that encourage action from within and support resilience.
A spoken line becomes a seed, and through practice, words become something users can truly use. English Ear° Trail helps users improve their English while also cultivating the spirit of practice itself.
Empathy Interface Personal: Visualizing Your Own Growth
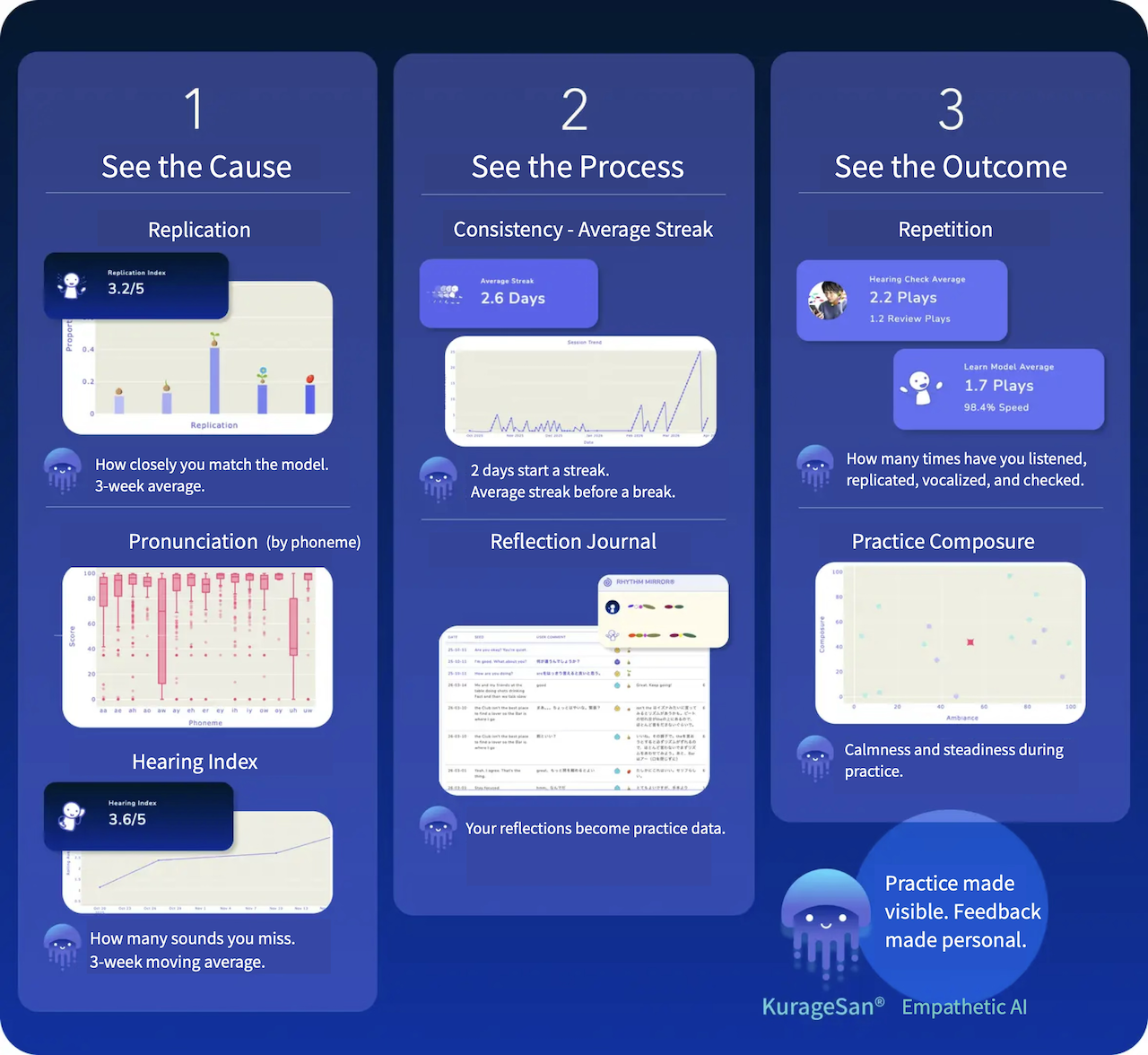
People helping themselves, people helping them, and AI gently supporting the connection.
Empathy Interface Personal visualizes the whole practice process — from results, to process, to causes.
It is not a data dashboard that simply displays measurable results and scores.
It reflects what ordinary scores cannot show: the user’s voice replication, changes in listening, continuity, reflection journals, repetition patterns, and the causes behind improvement.
Users can see their own change and notice what is happening. Tutors and educators can understand each user’s condition, encourage them, and offer more precise guidance. Empathetic AI KurageSan further supports that guidance.
Cultivate self-agency. Support others. Let AI support those who support others.
Empathy Interface connects spoken lines, practice data, reflection, and advice. It is not just an analysis screen — it is an interface for empathy, a platform that links practice with mutual support.
How 15- and 16-Year-Old Students Grow into Tutors at Empatheme Lab
Led by SomniQ CEO Rikko Sakaguchi, the Co-Creative AI English Science & Art Lab at Chiyoda Junior and Senior High School is not an English conversation lesson, nor is it a conventional English class.
It is a lab where students practice independently, notice changes in themselves, and genuinely improve their ability to hear and speak English.
At the same time, they study the very process of improvement and continuity through their own practice data.
In 2025, the Lab showed measurable gains in listening and speaking. Students practiced almost every day for more than 300 days, leaving reflection journals that show the process of continuity and improvement.
By visualizing the whole practice process — their own voice, continuity, and reflection — students begin to move from practicing only for themselves to supporting others. Fifteen- and sixteen-year-old students grow into tutors.
This process is supported by Empathy Interface, which makes practice visible and turns personal growth into shared guidance.
See the 2025 practice and research presentations, including the introduction video, here.
Learn more about the ongoing Co-Creative AI English Science & Art Lab for 2026, here.
Learn more about Empathy Interface, including the introduction video, here.
English Ear° Kids: Practice That Begins with Voice, Grown Together by Parents and Children

Built on the same concept as English Ear° Trail, English Ear° Kids is designed for young children and elementary school students.
Language does not begin with reading. It grows by listening, imitating, and speaking out loud. At home, it can open up new topics and conversations between parents and children, while making authentic voice practice a natural part of everyday life.
English Ear° Kids is designed so that:
⚪︎Children can move forward on their own.
⚪︎Parents can enjoy it together and naturally watch over the process.
⚪︎It creates involvement that is neither leaving children alone nor forcing instruction on them.
⚪︎Children can practice with “visible voice,” without relying on text.
⚪︎It is built with high-frequency lines that children will want to say out loud.
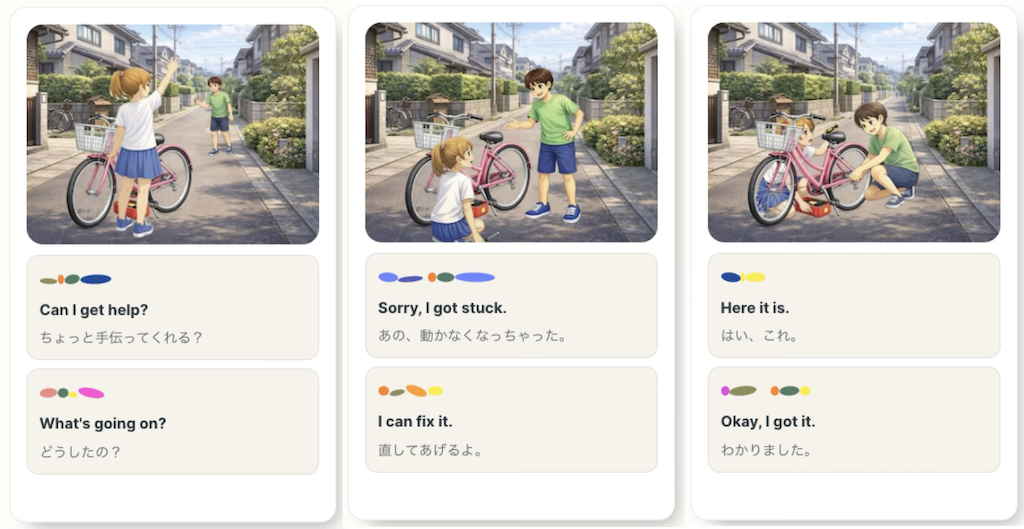

*English Ear° Kids content is now ready and currently available in limited release. Please contact us if you are interested in using, experiencing, or applying it.
Planned for the Second Half of 2026: New Forms of Content Created Through Visualization
Empatheme’s Multilingual Expansion: Japanese Ear° Trail for Richer Human Interaction in Japanese
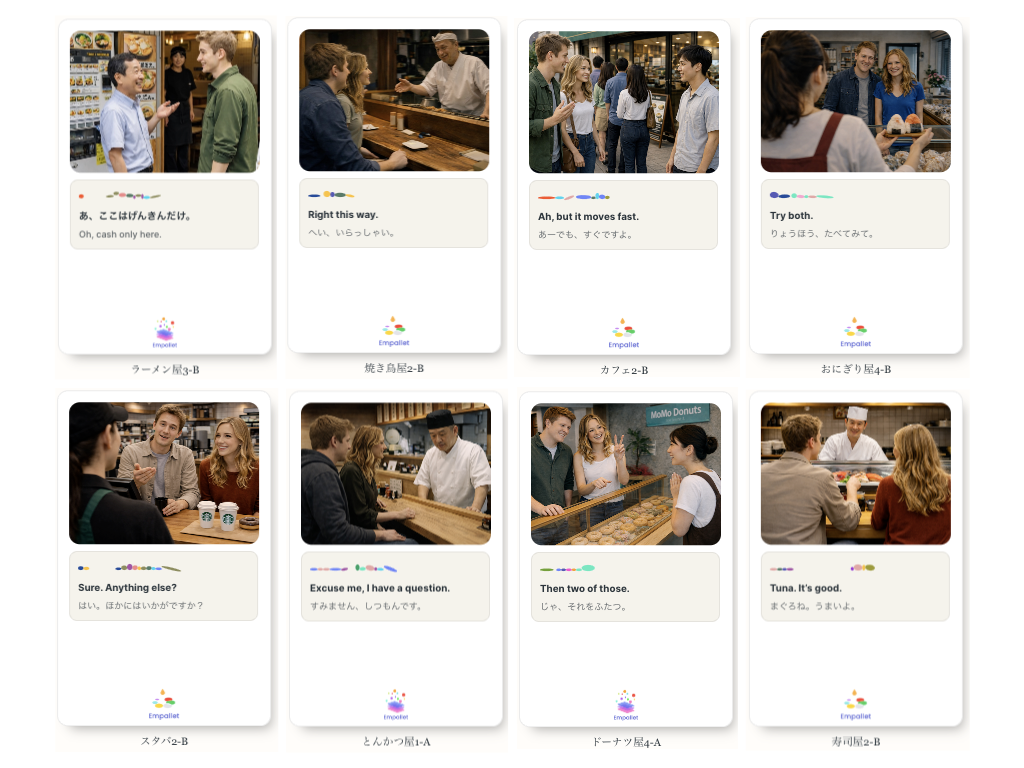
More than 40 million international visitors come to Japan each year, and over half are repeat visitors. Countless people love Japanese culture and want to enjoy “eating” and “visiting” experiences more deeply. Yet Japanese learning still has several barriers:
⚪︎Learning the language from written text can be difficult.
⚪︎There are few tools for imitating the rhythm of Japanese.
⚪︎There is little realistic content that lets people enjoy real-life situations.
⚪︎There are few ways to imitate real voices without relying on text.
Empatheme makes the sound and rhythm of Japanese visible through Rhythm Mirror, enabling a new form of Japanese Ear° practice that has not existed before.
Based on real voices in real situations, such as restaurants, users listen to short phrases, see the rhythm, and imitate the voice. It is a new cultural experience tool that lets people taste Japanese through voice and rhythm.
For people visiting Japan, as well as foreign residents living in Japan, Japanese Ear° Trail creates the enjoyment of wanting to “try using” Japanese in real situations. Trails modeled on actual shops and local places can use real voices and real scenes, helping people not only imitate Japanese, but also feel encouraged to visit the place and try the phrases there.
A single small spoken line can become the beginning of new communication with shop staff and local people.
English Ear° Music: Turning English Pop Songs You Once Only Listened to into Songs You Can Truly Sing
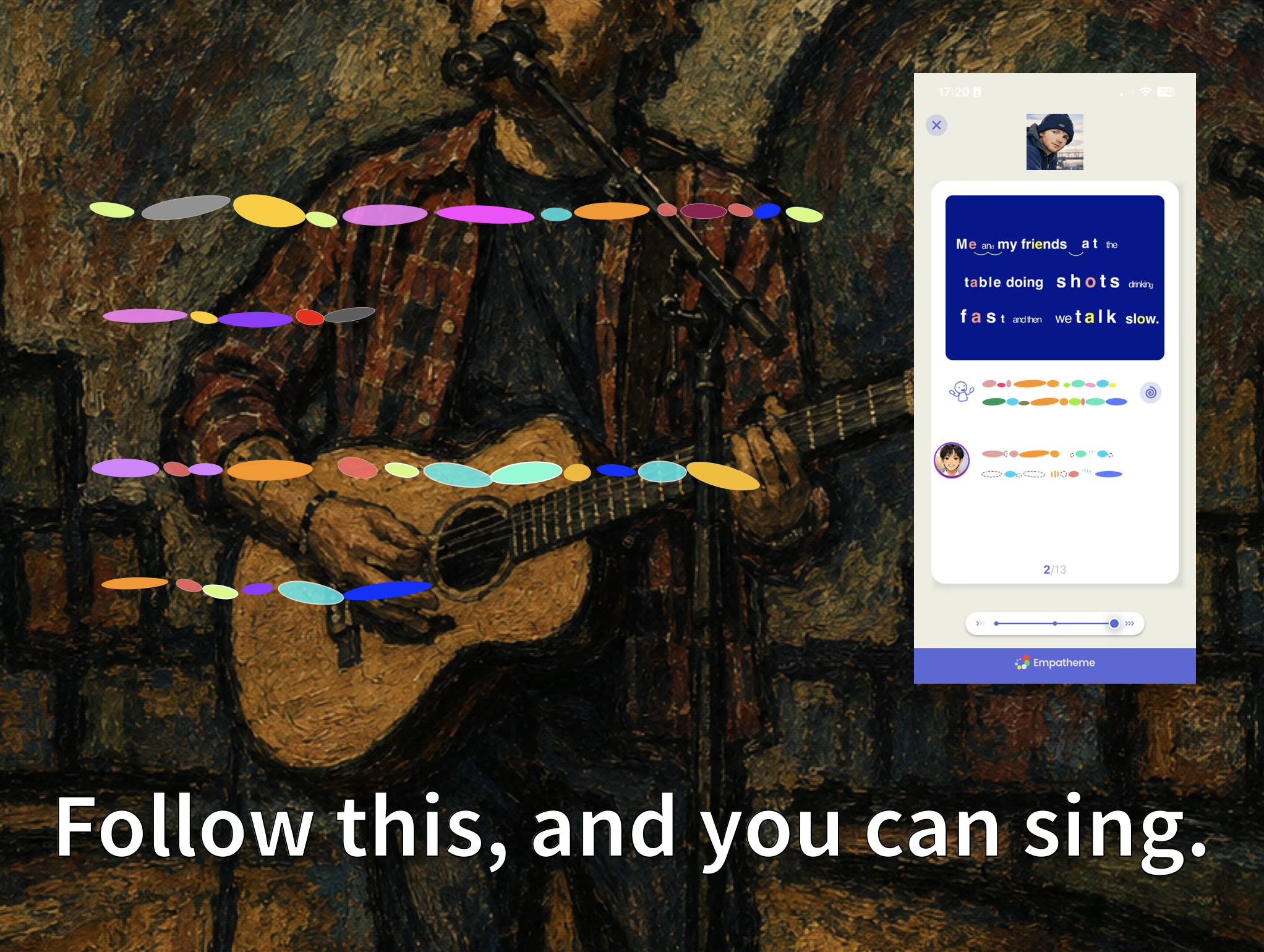
Have you ever felt this way?
⚪︎You listen again and again, but still cannot catch the lyrics.
⚪︎You look at the lyrics, but they do not match the sound. You cannot keep up.
⚪︎The rhythm quickly slips, and there seem to be too many words to fit.
⚪︎Even with a lyric video, your mouth cannot follow.
⚪︎You cannot remember the song as real phrases.
English Ear° Music is practice content for imitating songs phrase by phrase, without altering the original track.
By combining Rhythm Mirror, slow audio, and a cappella audio, English songs that you once only listened to can become songs you can sing yourself.
Even well-known songs that are difficult to sing, such as Ed Sheeran’s “Shape of You,” can become singable in just a few days. See the practice example from Empatheme Lab high school students here.
A New Medium for Giving Shape to the Irreplaceable Moments of Everyday Life Through Words in Voice — Empallet

In everyday life, there are words in voice that bring back a whole scene.
⚪︎A young son or daughter’s voice, only as it is today.
⚪︎A single spoken line carrying the feelings of a mother or father.
⚪︎Words exchanged with family or friends that stay in the heart.
⚪︎Words you want to send to someone. Words that stay beside them.
⚪︎Words that encourage you. Favorite lines.
⚪︎Lines you want to keep. Words you do not want to forget.
⚪︎Words that carry the thought behind a work or activity.
⚪︎A human encounter. A line that remains in memory.
Around a single voice, there is a scene. There is the presence of the people who were there. There are memories and episodes. The world is full of videos and articles, and we live in a constant flow of information. Yet the more important a word in voice is, the more easily it passes as a moment and disappears. Even when it remains somewhere, it is not usually in a form that we can return to, bring back into use, and share with others.
Empallet is a new experience tool that lets people create by combining voice lines and images. It turns everyday words in voice into episode-based card content that can be kept and opened in the palm of your hand.
Even an ordinary moment can become meaningful content by taking out a single spoken line and presenting it with an image, visible and moving voice, and a performed line — something valuable not only to you, but also to the people who care about you, support you, or follow your work.
The cards you create are not only for public sharing. They can also be shared safely within families, among friends, or inside small communities. At the same time, they can be delivered through share links or connected with social media, articles, and videos, expanding into learning, creative work, activities, shops, local communities, and cultural communication.
Empallet can be used across languages. Spoken lines appear as colored particles, and rhythm comes alive. This experience is supported by Empatheme’s invented technologies, including Rhythm Mirror, Context Mirror, and Empathy Interface.
Empallet is a new medium that preserves words in voice as memory and empathy, opens existing connections in a new form, and creates future connections. Those who already have works or activities can also express their thoughts in a new form by combining voice lines and images.
We welcome participation, cooperation, partnerships, and collaborations in creating content that brings out the power held in the human voice.
Resources and tips for creating Empallet content are available in the “Empallet” section of the Empatheme website.
▼ Now available for free. Download the Empatheme English Ear° Trail app here.
With Warm Up practice, users can enjoy a new dimension of visualization for free, including Rhythm Mirror, emp, and the experience of growing seeds.
English Ear° Trail also offers Trails 1 through 10. For a limited time, trail services and personal advice will also be provided free of charge.
Going forward, SomniQ plans to launch paid services in stages while offering various campaigns.
Download and Related Links
• App download (Google Play / App Store): https://api.empatheme.org/download
• Official website: https://ja.empatheme.org/
• About English Ear° Trail: https://ja.empatheme.org/english-practice/
About SomniQ

SomniQ, Inc. (Palo Alto, CA, USA)
Founded on November 10, 2012
CEO: Rikko Sakaguchi
CTO: Hidenori Ishikawa
SomniQ Co., Ltd. (Tokyo, Japan)
Founded on January 4, 2018
CEO: Rikko Sakaguchi
CTO: Hidenori Ishikawa
Vision & Purpose: Connecting Self-Agency and Empathy by Making Voice and Practice Behavior Visible
SomniQ, Inc. was founded in Silicon Valley in 2012. Ahead of the current AI era, SomniQ built a foundation for research and development by accumulating patented technologies in the United States, Japan, and other countries — technologies that support co-creative methods such as contextual feedback, visualization of speech features, quiet interfaces, empathetic response, and affordance design.
Since 2018, SomniQ has been conducting practical research and business development in Japan. Building on technologies that visualize the cognitive processes appearing in voice and behavior, the company now provides practice-support services, including English Ear° Trail.
By combining patented technology with practice data, SomniQ provides systems that connect the power to help oneself with the power to support others with empathy.
Corporate Website:https://ja.empatheme.org/en/about-somniq/