

Revolutionize Practice.
Self-Agency × Empathy

SomniQ is a Silicon Valley venture with research activities in the United States and Japan. For over 13 years, we have combined science and the liberal arts, putting humanity and technology at the core of our innovation.
Founded in Menlo Park in 2012, SomniQ built a solid R&D foundation before the AI era, creating a portfolio of co-creative method patents—including context feedback, dynamic speech visualization, stationary-state interfaces, empathic response systems, and affordance design.
Our principal technology is the Empatheme🌀 Interface®, a human–AI co-creative practice system centered on the patented Hearing Mirror®, Rhythm Mirror®, and Context Mirror®. These components are seamlessly integrated within a unified Journal–Dashboard platform, providing comprehensive visualization and support for human practice.
In 2018, we began service development in Japan, bringing our technologies from research into real-world applications. This year, we launched English Ear° Trail®—a platform that helps learners and educators build daily practice routines and experience English sounds and rhythm in new ways. Our products provide real-time and continuous feedback to encourage consistent, joyful learning.
With Empatheme, practice becomes a living medium for the dynamic interplay of self-agency and empathetic agency. As people practice, their actions, timing, and presence become shared assets, fostering mutual learning and social innovation—and advancing co-creative AI.
SomniQ seeks to lead this new ecology, where practice becomes culture and media itself becomes practice. Built on unique technology, IP, and the power of shared and accumulated practice data, we aim to set a new foundation for learning, content, and value creation through co-creative human–AI practice.
Patented IP Portfolio: Context-Generating Interface that Creates the Conditions for User-Specific Content and Communication
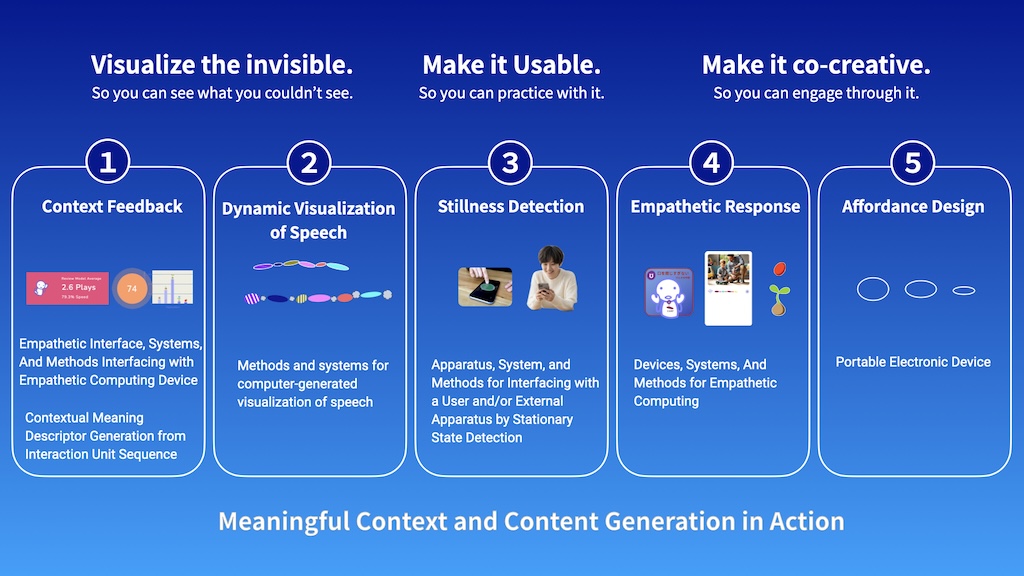
(1) Context Feedback

A method for generating contextual meaning descriptors from interaction unit sequence
1. Structural Extraction of Context:
Captures interactions as sequences of units to model and extract the user’s contextual states.
2. Multi-Scale Temporal Context Modeling:
Interprets context on both short and long timescales (from millisecond to years), allowing continuous and long-term interaction analysis.
3. Co-Creative AI via Implicit Behavior Sensing:
Senses users’ implicit prompts and nuanced behavioral expressions, creating a foundational interface for dynamic collaboration and co-creation between users and AI.
Patent Document Locations (PDF):
Empathetic Interface, Systems, And Methods Interfacing with Empathetic Computing Device US 10,409,377 B2
共感型計算装置とインターフェース接続するための共感型ユーザインターフェース、システム、及び方法-特許第6743036号.
(2) Dynamic Visualization of Speech

A method for extracting phonological and prosodic features from spoken utterances and presenting them through dynamic visualizations for comparison and real-time feedback.
1. Computer-Generated Visualization of Speech:
Captures and represents both linguistic (e.g., pronunciation) and paralinguistic (e.g., rhythm, tempo, intonation, segmentation, emotional tone) aspects of speech, transforming spoken language into dynamic visual feedback—whether processed in real time or post hoc.
2. Practice and Progress:
Analyze both cognitive and habitual speech patterns for users and educators. Speech—including pronunciation—can be compared to reference models, and users can practice and refine their skills through movement-based feedback on a smartphone app. Both users and educators can view progress over time, during live sessions or through later review.
3. Empathetic Interaction:
Detects and visualizes non-verbal contextual factors present during speech, supporting empathetic interaction with AI or between individuals through multimodal feedback.
Patent Document Locations (PDF):
Methods and systems for computer-generated visualization of speech US11,735,204 B2
Methods and systems for computer-generated visualization of speech US 12,374,352 B2
発話をコンピュータ生成によって視覚化するための方法およびシステム 特許第7611368
(3) Stillness Detection
A system that detects stationary state to recognize context and generate response.
1. Natural Stillness as Interaction Trigger:
Uses brief, unconscious pauses in human movement as a unique (patented) signal to prompt system recognition and response.
2. Extensible and Interoperable Design:
Functions across varied devices, interfaces, appearances, sensor types, and use cases, ensuring adaptability and broad compatibility.
3. Context-Aware Multimodal Sensing:
Initiates multimodal sensing when stillness is detected, guiding subsequent user actions in a naturally responsive and context-driven manner.

Patent Document Locations (PDF):
Apparatus, System, and Methods for Interfacing with a User and/or External Apparatus by Stationary State Detection
定置状態の検出によってユーザおよび/または外部装置とのインタフェースを形成する装置、システムおよび方法
(4) Empathetic Response

A system that extracts features of natural bodily movements and enables empathetic, multimodal responses
1. Empathetic Interaction via Natural Behavior:
The system detects and responds empathetically to users’ natural, unconscious body movements, fostering emotionally attuned interactions.
2. Multimodal Non-Verval Feedback:
Compact devices represent users’ bodily states across multiple sensory modalities, including light, sound, touch, and vibration.
3. Adaptive, Evolving Responses:
By dynamically weighting user behaviors and contextual cues over time, the system continuously refines and adapts its interactions for improved user experience.
Patent Document Locations (PDF):
Devices, Systems, And Methods for Empathetic Computing
エンパセティックコンピューティングのための装置、システム、及び方法
(5) Affordance Design

Affordance-driven product and interface design for eliciting bodily action and empathetic human–AI interaction
1. Compact, Palm-Fitting Design:
Small, tangible device that encourages intuitive physical interaction (touching, grasping, holding).
2. Omnidirectional Affordance:
Usable and inviting from any direction, enabling instruction-free, intuitive use based on approach and gaze.
3. Gesture Cues and Implicit Prompts for Human–AI Collaboration:
Promotes collaboration using body gestures and implicit behavioral prompts, enabling guidance and teamwork without explicit commands.

Patent Document Locations (PDF):
Portable Electronic Device D732,033 S Portable Electronic Device US D738.376 S
Portable Electronic Device US D864,961 S Portable Electronic Device US D940,136 S
意匠登録第1521298号 意匠登録第1575144号 意匠登録第1594394号
Patent IP in Action – Application and Service Implementations
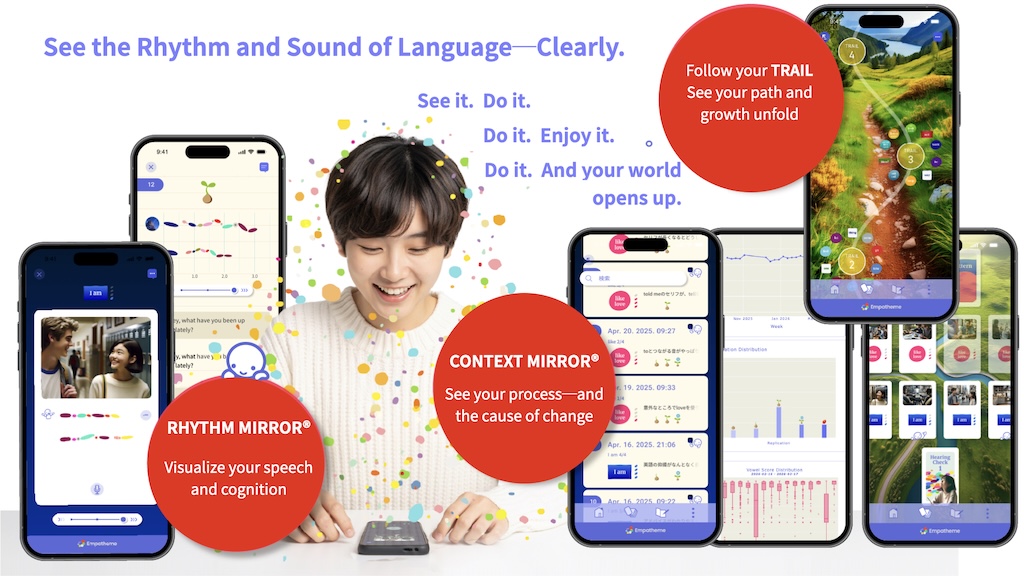
(1) Mirrors on English Ear°Trail®
These screenshots show how the patented Mirror technologies—Hearing Mirror®, Rhythm Mirror®, Context Mirror®, and EmpaJournal™—are fully integrated into the English Ear° Trail® platform. Together, they capture, visualize, and deliver real-time, continuous feedback on learners’ listening, speaking, and reflective behaviors, transforming daily practice into structured, traceable, and reusable data.

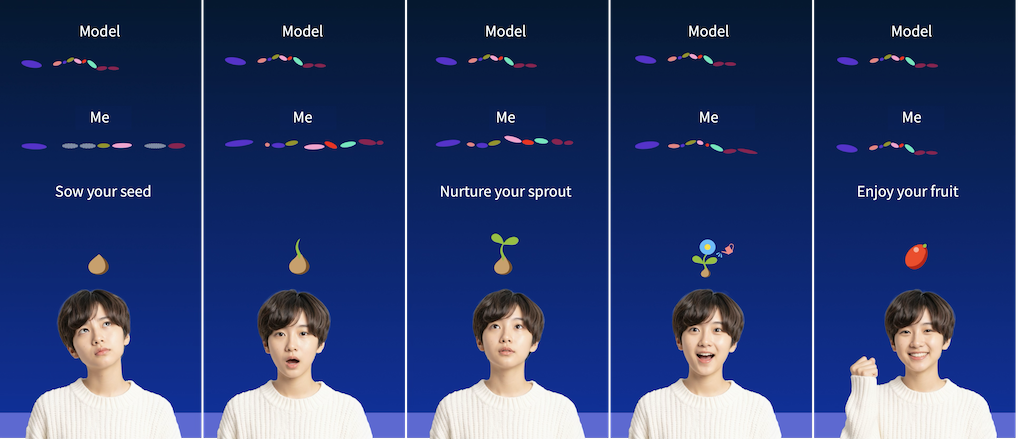
(2) Rhythm Mirror® and Seed Growth
This visual sequence illustrates how daily practice with the patented Rhythm Mirror® transforms repeated voice exercises—from imitation to growth—into compounding progress and lasting engagement. Each small action acts as a “seed,” nourished through continuous feedback, visualization, and reflection. This is made possible by the combined application of multiple patented technologies, which work together to create a cohesive and effective learning platform.
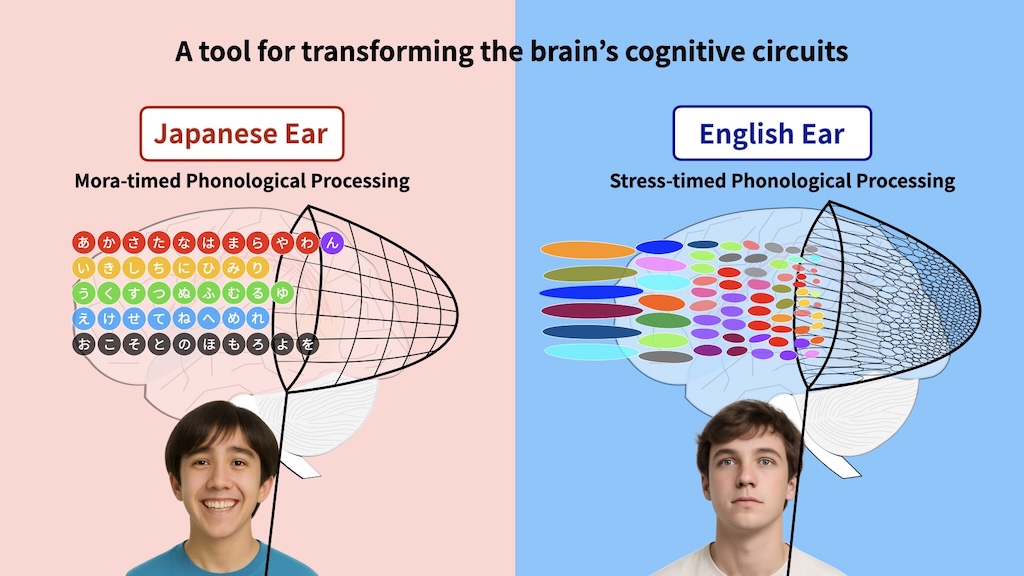
(3) Japanese Ear° vs. English Ear° in Practice
This comparison illustrates how the patented Rhythm Mirror® supports the transformation of phonological cognition from mora-timed to stress-timed processing, enabling users to practice, perceive, and internalize this shift through targeted rhythm replication and continuous feedback.
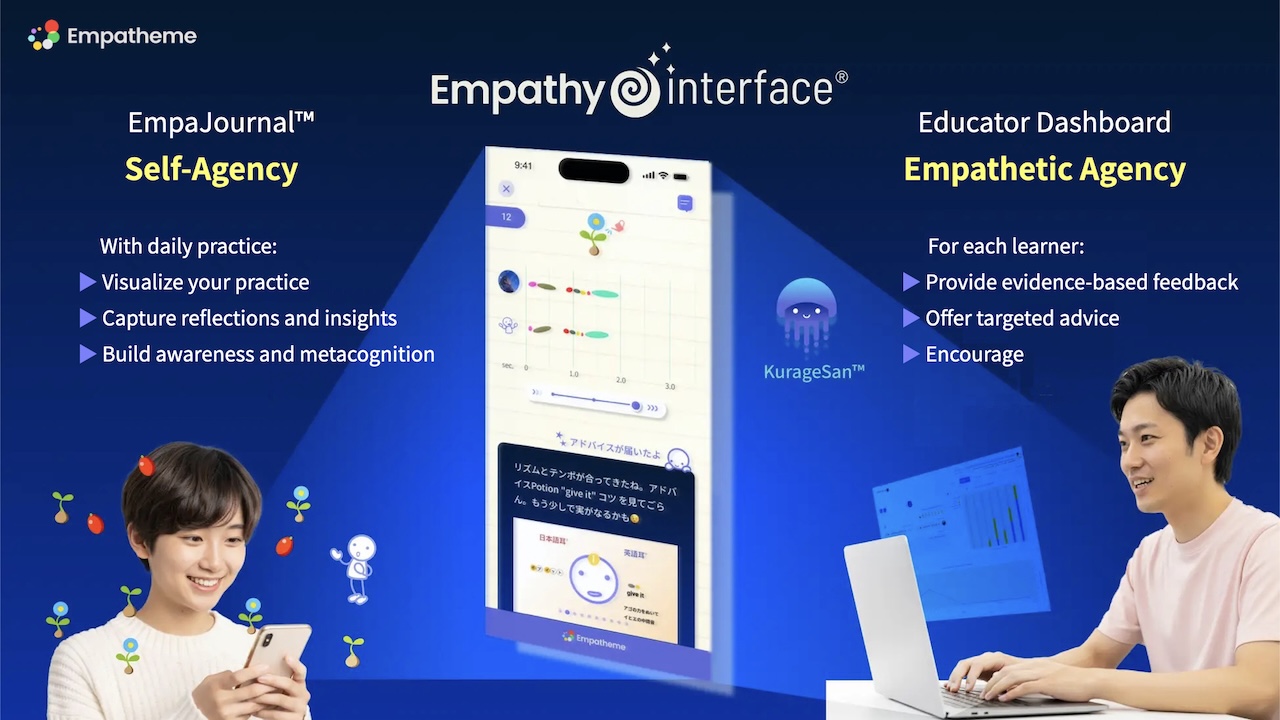
(4) Empathy 🌀 Interface®
The Empathy Interface® integrates the English Ear° Trail® app and Educator Dashboard into a unified, co-creative system. Leveraging the Context Feedback IP, the platform captures both learner interactions and educator responses as structured contextual signals. This architecture operationally links the Empa-Journal™ (learner’s practice field) with the dashboard (observation and guidance interface), enabling continuous system-level integration of self-agency and empathetic agency throughout the learning process.
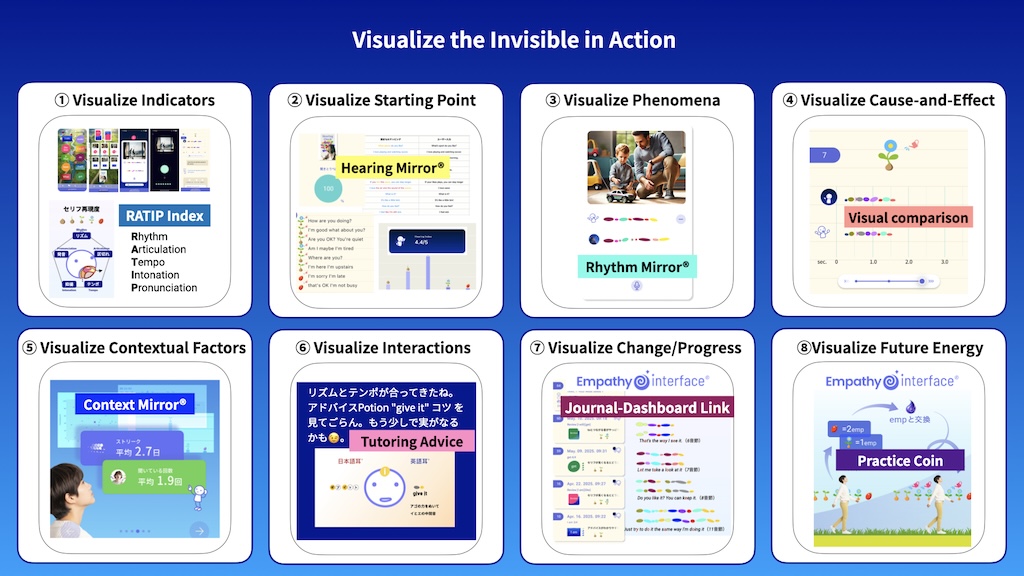
(5) Visualize the Invisibles
This visual summarizes how Empatheme’s patented technologies operate as a unified system—turning invisible practice processes into structured, actionable data. Through continuous sensing, visualization, and feedback, progress is not only observed but also accumulated, evaluated, and compounded into measurable growth. The practical integration of multiple intellectual property components enables each example.

From Background Story to Path Forward – By Rikko Sakaguchi
I. ORIGIN
(1) The Origin of the Mirror
My pursuit began when I was four years old. One day, my father brought home a Sony open-reel tape recorder. I can never forget that surprising sensation. When I first heard my recorded voice, I felt as if I were the voice in the box. From then on, with the English tapes my father brought home, I played by recording and listening to my own imitations. This became the first seed of my “English ear,” and of Empatheme. Every night, I dreamed of entering Granma’s shortwave radio and flying across the world map by becoming one with English.

(2) Loss of Spoken Language
When I was sixteen, I moved to the United States for high school. I had hoped to pursue further study in graduate school, though I didn’t yet know in what field. But I was already fascinated by the science behind language. That path was cut short when I had to return home unexpectedly because my father fell gravely ill. He became paralyzed and developed severe dysarthria, losing the ability to speak while his mind remained sharp. Until his passing, we relied on a hiragana letter board to help him move his hand to point to letters, along with the minimal expressions we could—fingers, breath, eye movements, and the smallest gestures—to communicate. Even in the depths of our helplessness, we somehow found moments of hope.
(3) What if we Visualize the Invisible?
During those long years, I learned something irreversible: meaning does not originate solely from words. It lies in rhythm, timing, posture, breath, hesitation, and all the subtle, surrounding contexts that exist alongside and beneath spoken language. From the helplessness of wanting to help but being unable, a single wish took root in me: I want to make voice visible—to reveal a human presence before it fades away.
II. LAW
(4) The Law of “Now or Never.”
Sony—the birthplace of the box that had first captured my voice, created by the co-founders Masaru Ibuka and Akio Morita—became the next stage of my life. On my very first day, however, Akio Morita, through HR, ordered me to undergo a full year of simultaneous interpretation training. By day, I did my regular work. By night, I trained my brain to its physical limits. There, I encountered a brutal truth. Listening happens only once—sound vanishes instantly. Speaking also occurs only once—you cannot rewind your own utterance. Only reading and writing escape real time. Language is constantly reconstructed in fleeting moments. It is always a matter of now or never, practiced repeatedly. This reality becomes clear only when you step into a second language.
(5) Technology’s Limit—and Human’s
Twenty years later, I was leading global engineering for mobile and smartphone development at Sony Ericsson. It was there that I realized another fundamental law: technology works only when there is explicit input to generate output. But why does this matter? Because humans can only input what they can capture, there is no way to input what they are not aware of. If you don’t even know it yourself, then no one else can know it, either. This led to a deeper, unavoidable question: how do we become aware of what is implicit—and how can what’s implicit become usable as input?

(6) Form and Shadow
My father used to mentor me from childhood with a vital phrase, quoting a Zen saying: “If the form stands true, the shadow will reflect it as it is” (形端影直). Years later, when I faced that deeper question, his words returned with new clarity and inspiration. You cannot create the shadow alone. Form always emerges within context—interaction, continuity, relationships, and many causes, some known and others unknown—even if we aren’t fully aware of them. From that, a shadow naturally follows.
My connection with Zen quietly deepened over the years through my brother, a Zen master, who taught me mindfulness and how to unlearn ingrained habits. His guidance reflected Zen’s spirit: encouraging self-inquiry rather than offering answers or methods. Zen expresses this: “Nothing is hidden, everything is manifested”(遍界不曾蔵). Yet this revealed the challenge most people face—recognizing their own unawareness. Still, self-practice is essential. Seeking a way to bridge the gap between personal insight and practical application became the central focus of my work.


III. MIRROR
(7) Building a Mirror
A mirror—that was the answer: to create a mirror that could reflect the invisible. To directly address this challenge, I founded SomniQ with my colleague Hidenori Ishikawa. For thirteen years, we pursued—through patient trial and error—a way to reflect reality as an actual mirror. Not metaphorically, but by making the invisible visible: voice, demeanor, timing, rhythm, intention, and the cognitive processes that unfold within real situations. This meant capturing not only unconscious behavior, but also patterns of expression and interaction as reproducible data, and reflecting them within their living context to foster self-awareness.
A mirror—that was the answer: to create a mirror that could reflect the invisible. To directly address this challenge, I founded SomniQ with my colleague Hidenori Ishikawa. For thirteen years, we pursued—through patient trial and error—a way to reflect reality as an actual mirror. Not metaphorically, but by making the invisible visible: voice, demeanor, timing, rhythm, intention, and the cognitive processes that unfold within real situations. This meant capturing not only unconscious behavior, but also patterns of expression and interaction as reproducible data, and reflecting them within their living context to foster self-awareness.
(8) The Mirrors that Reflect Human Agency
Out of this pursuit emerged a family of patented inventions—Hearing Mirror®, Rhythm Mirror®, Context Mirror®, together with the Empathy Interface® that connects them. These Mirrors make the invisible visible—revealing elements such as voice, demeanor, cognition, and surrounding contexts —and turning them into something observable in practice. These are not merely tools, but a co-creative framework that bridges the practitioner’s self-agency with the empathetic agency of educators and researchers who observe, support, and reflect on practice. By “empathetic,” I mean that beyond explicit exchanges of merely giving answers, humans and AI—and humans with one another—can share implicit signals of context, intention, and presence. The mirror does not judge. It simply shows what is happening now, in the past, and what may come next, at any time.
(9) Self-Agency Through Language
Language learning—and all human learning—rests on self-agency. Teachers, technology, and AI can support and guide you, but they are not you. They do not live your life or experience your practice within your body or mind. What we call learning is, in truth, transformation—shifts in perception, cognition, and capacity—possible only through your own embodied practice. Actual progress begins when you are supported in activating self-agency and building daily practice with your own voice.
(10) Revolutionizing Practice through Empatheme®
“Too much teaching, too little help for practicing.”
Let us listen to the silent voice—the implicit longing for care around practice.
It is one real issue—but it sits on top of deeper, unconscious constraints, quiet forces that shape learning without our awareness.
To truly change the practice of learning, we must drive social innovation—changing the underlying conditions that constrain both learners (unrealized needs) and educators (limited capacity).

Our vision is to revolutionize practice through Empatheme®—a co-creative, multidimensional ecosystem that generates the mutual dynamics between self-agency and empathetic agency. Within this ecosystem, the structure itself becomes a new learning infrastructure, and the act of practice becomes a form of experience media—something people participate in socially and co-creatively—across cultures and contexts, not just individually.
By turning play into practice-driven learning, enabling co-creation between self and others, self and AI, and connecting people through layered matchmaking, Empatheme opens a new practice that grows from within life itself.
Empatheme evolves along three dimensions:
(1) The Connected Practice Network:
A horizontal matchmaking model around practice. Learners connect directly with supporters—educators, peers, mentors, and sponsors—beyond the traditional vertical teacher–student structure. Support circulates through daily practice, making learning relational, continuous, and sustainable across borders and roles. Educators become not just instructors but creators, offering practice-based content grounded in their own expertise.
(2) Practice as Experience and Entertainment:
Learning emerges within culture and media—stories, films, drama, manga, anime, and games—where practice arises naturally through experience. When Mirrors are embedded into content, practice and experience merge.
Watching becomes interacting. Enjoyment becomes training. The narrative no longer unfolds identically for everyone; it changes with how one listens, speaks, moves, and engages in each moment. Practice enters culture as play, not obligation.

(3) Co-creative AI as a Social Innovation:
Together, these three dimensions form a new social innovation. This ecosystem changes the conditions of practice itself, not by making learning appear enjoyable from the outside, but by turning genuine engagement into practice, restoring the connection between experience, agency, and growth. Empatheme® pioneers this shift, where practice grows from within life, media becomes practice, and collective human participation becomes the foundation of co-creative intelligence.
About SomniQ

SomniQ, Inc. (Palo Alto, CA, USA)
Founded on November 10, 2012
CEO: Rikko Sakaguchi
CTO: Hidenori Ishikawa
SomniQ Co., Ltd. (Tokyo, Japan)
Founded on January 4, 2018
CEO: Rikko Sakaguchi
CTO: Hidenori Ishikawa

Personal Profile
2018-Present: CEO, SomniQ Japan
2017-Present: Executive Director, Empatheme Foundation
2012-Present: Founder & CEO, SomniQ, Inc.
2002-2012: EVP & Chief Creation Officer, Sony Ericsson Mobile Communications
1999-2001: Corporate Strategy Manager, Sony Headquarters
1990-1999: Marketing Director, Sony Mexico/Sony Spain
Academic Publications (PDF)
Empatheme Data Collection Method and Applications of English Learner Data
無意識的な活動から気づきを誘発する学生実習プログラム開発(工学教育論文)
Philosophy Inspires Technology Innovation – The Enryo Learning Experience on Empatheme Method
技術イノベーションを導く哲学:エンパシームメソッドによる 「円了学舎」の実現
Original Writing Archive (Empallet)
A digital archive for practice innovation with 2,000+ original visual entries combining short “seed” phrases authored by Rikko Sakaguchi